






















Edit: Numbers have changed since publication.
Big Data Analytics is mainly concerned with symbolic processing of vast data for cumbersome problems like targeted advertisements, learning straight forward correlations, and recommendation systems. With the advent of scalable, distributed computing, data scientists are also keen to intelligently manage information that is captured in text, speech or other completely unstructured forms. Cognitive Analytics, as we call this field, has much larger potential compared to Big Data Analytics. It is also more challenging.
Coseer's technology distils relevant information from disparate sources and presents in an easy-to-use, simple form to improve productivity, save valuable time and resources, and reduce response time for enterprises and individual users. Please click here to read more about our design philosophies. In this post we discuss why Cognitive Analytics is more challenging than Big Data Analytics.
Probabilistic Computing vs. Deterministic Computing
The answers to analyses conducted using Big Data are usually deterministic i.e. given a set of assumptions and rules a machine will give a reliable output. The trick is to get the right set of assumptions and rules, and to program the machine or cluster in a resource efficient way.
We are not so lucky. Cognitive Analytics deals with problems that are inherently uncertain in nature and thus the solution is necessarily probabilistic.
Consider this example. Coseer uses Noun Phrase Chunking to identify key topics in a corpus and use them to learn associations between different parts of a textual corpus. We took content of all the URLs that a popular Wall Street handle tweeted over a week. We fed this content to two platinum standard Natural Language Processing (NLP) packages – Stanford NLP and Ling-Pipe. The results are counter-intuitive.
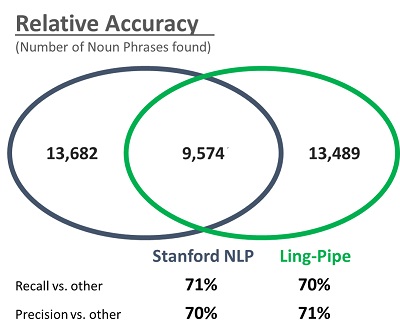
In other words, we can only be ~70% confident that any noun phrases extracted by industry standard NLP tools are accurate. This is one reason we focus on corpus based processing. The more data points we have the higher our confidence becomes in the output.
Difficult to Map-Reduce
Unlike Big Data Analytics most Cognitive Analysis tasks do not render themselves to map-reduce style of distributed computing. Due to completely unpredictable, unstructured and string-based data the computational complexity of the reduce step tends to be the same order of magnitude as the complexity of the original problem. For example, for a simple problem of finding the phrase from a corpus with the highest TF-IDF each node in the cluster will output a data-structure that is almost as bulky as the input corpus, making it necessary that the node used for reduce step is very powerful.
Ergo, Cognitive Analytics systems should be designed to execute as much as possible in a single node and use problem-specific distributed architecture where needed. That is partly why IBM Watson is a hardware based solution, a derivative of the Blue Gene supercomputer. This is also one of the reasons that Google, Facebook, Apple and other companies dealing with a lot of text design their datacenters using super-fast, flash based Direct Attached Storage rather than prevalent network storage (SAN or NAS).
Coseer takes an engineering approach to the problem. For the step of Noun Phrase Extraction, we use our own Coseer Tagger. We compare to the platinum standards as below.
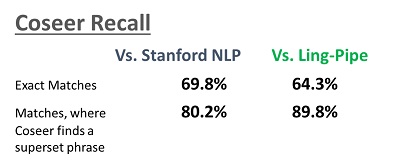
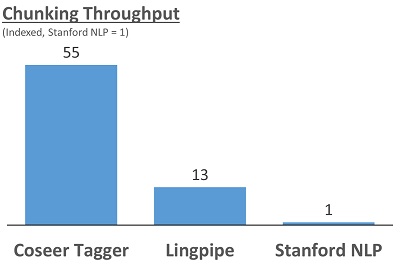
What we give up marginally in accuracy, we make up with our corpus based approach. However, this technique is far superior in terms of time taken. The graph below demonstrates it. Given that we need to process billions of sentences, this superiority becomes a defining factor in our solutions. This approach is very memory efficient as well.
Need For Context Aware, Interactive Design
Many Big Data Systems are employed to make decisions once trained. Due to the probabilistic nature of tools available, Cognitive Analytics Systems must be designed for higher interaction, not only for learning, but also for making decisions. Such interactivity increases the users’ confidence in the system, improves accuracy of results and reduces some of the complexity challenges. The interactivity also provides the context for further improvement.
Similarly, output from Cognitive Analytics should come with attached confidence intervals. Alternatively, such systems should report multiple options and let the user choose among them. Such considerations increase the challenge of software designers to include features for easy interactivity.
Like Big Data Analysis Systems, Cognitive Analysis Systems are more effective and accurate when domain-specific information is used in training so that the inference is tuned to the specific structure and needs of the problem under consideration.
Cognitive Analytics, as a field, is developing fast, and a lot of more exciting things are yet to come. Keep in touch with the latest by following us on Social Media.